Armorer: A Minimal, Performant KJV Web Reader
Every now and then I find myself needing to look up a verse or passage while sitting at my computer. Although there is an App For That (TM), I’d rather pull it up quickly in the browser I already have open. The standout web reader for this is ESV.org, with a classy dark theme, nice clean uncluttered design, and… only one Bible version.
Now, I have nothing against the ESV, but I do have a fondness for the King James and its enduring legacy. However, the web readers available for the KJV are generally terrible, with cluttered pages, no dark theme, and way too many features.
The Foundation
Because I have no plans to monetize this with ads, paid subscriptions, etc., we need to keep infrastructure costs to a minimum. A static site hosted for free on GitHub Pages is a great place to start. We’ll use Eleventy to build the site, and leverage The SWORD Project for the KJV source material.
A preprocessing script loads the KJV module, parses out the chapters and cleans up the formatting, and then generates a JSON data file for Eleventy with the chapter metadata and contents.
Then, we have some simple templates that generate chapter pages from that data file:
---
layout: base
meta:
type: "chapter"
pagination:
data: bible.chapters
size: 1
alias: chapter
permalink: ""
eleventyComputed:
title: "Armorer | "
pageHeader: "Chapter "
prevPage: ""
nextPage: ""
meta:
description: "A beautiful minimal Bible reading experience."
---
<div id="content" class="position-relative d-flex" data-chapter="" data-next-chapter="" data-prev-chapter="">
<div data-intersection-trigger class="pe-none position-absolute top-0 start-0 end-0" style="height: 50vh;"></div>
<main class="container">
<header class="sticky-top">
<!-- this nested div is a hack to fix 1px gap with sticky header -->
<div class="bg-dark fw-bold p-2 position-relative" style="top: -2px;">
<a href="" class="link-light"></a>
⟫
<a href="" class="link-light">Chapter </a>
</div>
</header>
<article>
</article>
</main>
<div data-intersection-trigger class="pe-none position-absolute bottom-0 start-0 end-0" style="height: 50vh;"></div>
</div>
Do the same thing to generate table-of-contents pages for each book, and for the list of books of the Bible, and we have a solid HTML foundation. (And CSS: I’m using Bootstrap here for simplicity.)
Infinite Scroll
The ESV.org reader automatically loads new chapters as you scroll down, letting you keep reading without clicking a “next page” button. This is a really nice modern touch. What does it take to implement this in a static site?
Surprisingly little!
The trick is to know what the next and previous chapters should be. This is easy enough to add to our JSON data for each chapter, and then we can add it to our Eleventy template as a data attribute.
Then loading the content for the next chapter is easy:
// from class InfiniteScrollSection
const base = baseUrl();
const res = await fetch(base + this.chapter);
const html = await res.text();
const parser = new DOMParser();
const doc = parser.parseFromString(html, 'text/html');
this.title = doc.title;
this.content = doc.getElementById('content');
Fetch the data, parse it as HTML, and get the content div. Now we can insert it before or after the current chapter in the DOM and we’re set.
Scroll Position
Well, almost. If you have started scrolling down the page, then inserting a new chapter before the current position will not change your scroll position - the chapter you’re currently reading will stay exactly where it is in your screen. But if you haven’t started scrolling yet, everything will be shifted down automatically and you’ll see the newly-loaded chapter.
That’s not what we want. So, in that case, we need to force the scroll position to stay the same:
// insert content into dom before next chapter or after previous chapter
const nextChapterDom = this.nextChapter && document.querySelector(`div[data-chapter="${this.nextChapter}"]`);
const prevChapterDom = this.prevChapter && document.querySelector(`div[data-chapter="${this.prevChapter}"]`);
if (nextChapterDom) {
const scrollElement = document.querySelector('#site-content');
const scrollPos = scrollElement.scrollTop;
nextChapterDom.parentNode.insertBefore(this.content, nextChapterDom);
scrollElement.scrollTop = scrollPos + this.content.getBoundingClientRect().height;
} else if (prevChapterDom) {
prevChapterDom.parentNode.insertBefore(this.content, prevChapterDom.nextSibling);
} else {
console.error('Could not find insert position for chapter', this.chapter, 'between', this.nextChapter, 'and', this.prevChapter)
}
If we’re inserting a chapter before another chapter, we’ll record the scroll position and then update it after the new chapter is inserted. (One minor issue I ran into here: margin collapse means that the actual height change may be greater than the chapter’s getBoundingClientRect height if a component inside the content div has a margin that leaks out. The fix was adding display: flex; to the content div to prevent those margins from leaking.)
Intersection Observer
Now we can load content for the next and previous chapters, but we really only want to do that when the user starts reading a new chapter. What we want is an Intersection Observer. This triggers events when a specific element scrolls into a viewport.
this.observer = new IntersectionObserver((entries, observer) => {
if (!entries.some(entry => entry.isIntersecting)) return;
// create new previous/next chapters (automatically added to sections map)
if (this.nextChapter) new InfiniteScrollSection(this.nextChapter);
if (this.prevChapter) new InfiniteScrollSection(this.prevChapter);
}, {
threshold: [0],
root: document,
rootMargin: '0px'
});
this.observer.observe(this.content);
Now, when the content div for a given chapter scrolls into the viewport, we’ll create a new InfiniteScrollSection for the next and previous chapters. This class automatically short-circuits if it’s already been instantiated for a particular chapter, to avoid duplicates. When created, it automatically loads the content (as above) and inserts it into the correct place in the DOM, either after its previous chapter or before its next chapter.
But this doesn’t change the URL in the browser: you might start in Matthew 1, scroll down as you’re reading, and end up in Matthew 5, but the URL still shows Matthew 1 and will take you back there if you refresh the page. It would be better if the URL updated once we have mostly scrolled into a new chapter.
You might think we could just set a new threshold to 1 (100%) and as soon as the chapter fills the viewport it will trigger. This is not what actually happens. The intersection threshold means that 100% of the chapter must be inside the viewport - and if the chapter is longer than the viewport, that will never trigger.
We could do some trickery with calculating the chapter’s height and figuring out the threshold that would actually fill the viewport, but there’s an easier solution: we’ll just create some invisible divs at the top and bottom of the chapter that are 50% the height of the viewport and use those as our triggers:
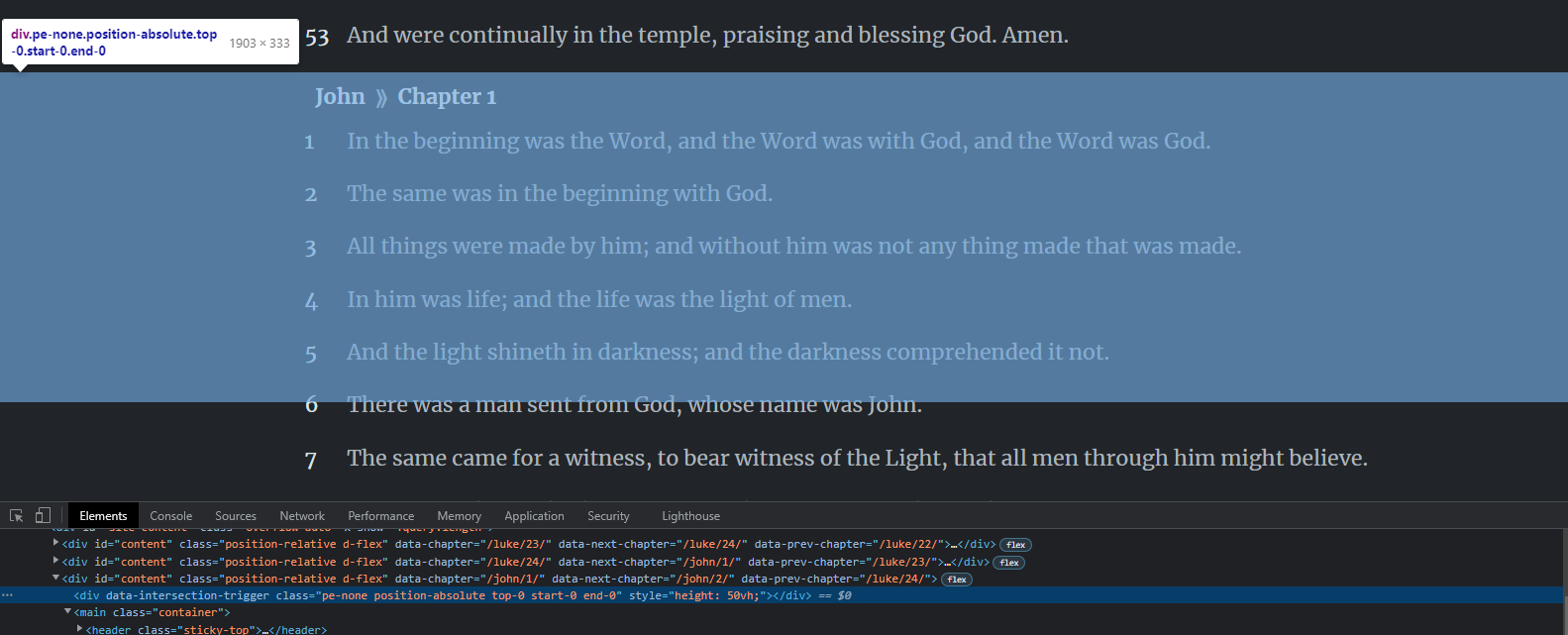
Full-Text Search
We’ll provide a single search box with two modes: Go To Reference and Full Text Search.
A user can enter a reference (e.g. “Genesis 1:1”), hit enter, and go directly to that verse. This supports abbreviations and variants thanks to the chapter-and-verse npm package.
Alternatively, the user can enter a search query and browse the results from anywhere in the Bible (not just loaded chapters).
Since this DOM manipulation is getting a little more advanced, we’ll rely on AlpineJS to simplify the work.
Go To Reference
This part is simple enough: it’s a matter of running the user’s query through chapter-and-verse and, if it matches a reference, generating the normalized URL that points to that reference. This is triggered by a keyup.enter directive in Alpine.
Search Index
The search index requires a little more effort. Normally, a search would run on the server-side, so large indexes could be built and queried without transmitting all that data over the wire. A full-text search index will not be smaller than the text itself, so the client-side requirement means we need to load that data.
I experimented with a few different libraries including Lunrjs and Fuse.js before settling on js-search. This has a “web-worker optimized” version called js-worker-search, but I opted to implement the web worker on my own for more control.
Why a web worker? Searching is a computation-heavy process, and if run in the main thread it blocks user interaction. If we run it as the user is entering their search query, this means the input hangs after each character until the search updates - a terrible user experience. Instead, we run search in a web worker, which executes in a separate thread and posts the results back asynchronously.
Downloading the data - a json file of all verses and references in the King James, which clocks in around 4.5MB uncompressed - is painful, especially on a throttled mobile connection. Fortunately, being mostly text, the default gzip compression provided by GitHub Pages reduces that to a more manageable 1.4MB. Caching helps further, though the caching policy for Pages refetches after 10 minutes and is not configurable. We load this when the web worker is initialized, after the page is rendered, so it can load in the background as the user browses the current page.
Conclusion
Eleventy and Alpine provided a simple and efficient platform for a minimal-JS static site. Sometimes, it’s nice to strip out the heavy frameworks and get back to the basics of client-side code. Implementing infinite scrolling with just a little Javascript was immensely satisfying. I fell back to Alpine for some of the DOM manipulation around search results, but that may be worth experimenting with in the future as well.
What does the future hold for Armorer? At this point it’s mostly feature complete; there are a few optimizations I still have in mind, and I’ll no doubt find bugs as I use it. I am considering adding settings to configure color scheme, hiding verse numbers, etc. I may experiment with zero-JS fallback functionality - navigation buttons instead of infinite scrolling - but this will break search/go to reference, so I’m not sold on that idea.